A pipeline in Azure
Data Factory (ADF) is a logical grouping of activities that together perform a
task. In this article, we are going to learn the steps to create a ADF
pipeline.
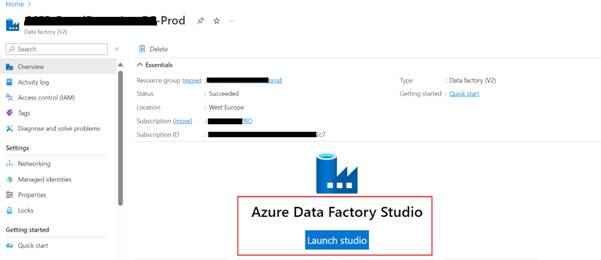
- Log into
the Azure portal: https://portal.azure.com/
- Open
Azure Data Factory Studio and
navigate to your Azure Data Factory instance. Once there, open the Azure Data
Factory Studio.
Create a New Pipeline
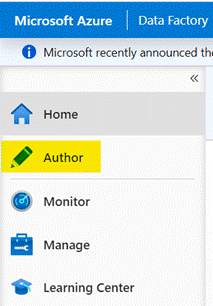
- Go to the Author tab:
In the ADF Studio, select the “Author” tab on the left-hand side.
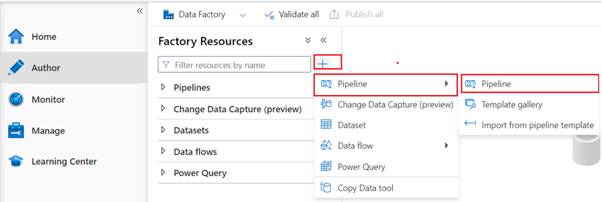
- Create Pipeline:
Click on the “+” button (Create new resource) and select “Pipeline”.
Add Activities to the Pipeline
- Choose Activities:
In the pipeline canvas, you will see an assortment of activities you can add to
your pipeline, such as Copy Data, Data Flow, Execute Pipeline, ForEach Loop,
etc.

- Drag and Drop
Activities: Drag and drop the desired activities onto the
canvas.
- Configure Each
Activity: Click on each activity to configure its settings,
such as source and sink datasets for a Copy Data activity, or the specific details
of a stored procedure for a Stored Procedure activity.
- Set Properties:
For each activity, set the required properties in the settings pane. This might
include linking to datasets, linked services, and specifying parameters.
- Connect Activities:
If your pipeline has multiple activities, you can connect them to define the
order of execution. Drag the green output handle from one activity to the next
to create a success link.
Parameterize the Pipeline (Optional)
- Create Parameters:
You can create parameters for your pipeline and use these parameters within
your activities for dynamic behavior.
- Assign Values:
Assign values to these parameters at runtime for flexibility, especially useful
when the same pipeline is used for different scenarios or datasets.
Validate and Debug the Pipeline
- Validate Pipeline:
Use the Validate button to check for errors or issues.
- Debug:
Use the Debug option to test run your pipeline. Debugging allows you to run the
pipeline in the ADF UI and see the results without having to publish or trigger
the pipeline fully.
Publish and Trigger the Pipeline
- Publish:
Once your pipeline is ready and tested, click on the “Publish” button to save
your pipeline to the Data Factory service.
- Trigger Manually or
Schedule: You can manually trigger the pipeline or create a
trigger (schedule or event-based) to run it automatically at specified times or
in response to certain events.
Best Practices
- Modular Design:
Keep your pipelines modular by breaking down complex workflows into smaller,
reusable pipelines.
- Error Handling:
Implement error handling in your pipelines using activities like the “If
Condition” or “Set Variable” to manage and respond to failures.
- Monitoring:
Utilize the monitoring features in ADF to track pipeline runs and performance.
- Documentation:
Maintain clear documentation for each pipeline, explaining its purpose, design,
and any important configurations.