Integration Runtime (IR) in Azure Data
Factory is essentially the execution environment where the data movement, data
transformation, and dispatch activities occur. Understanding the types of
Integration Runtime and their specific use cases is a key to effectively
leveraging Azure Data Factory.
Types of Integration Runtime (IR)
- Azure Integration Runtime:
- Purpose: Primarily used for data movement between cloud-based data
stores, and also for dispatching activities to external compute services
like Azure HDInsight, Azure Databricks, or Azure Machine Learning.
- Location: Runs in Azure public cloud.
- Use Cases: Ideal for copying data across
cloud data stores (e.g., Azure Blob to Azure SQL Database), or when using
cloud-based transformation services.
- Scalability: Automatically scales to
meet the data integration workload.
- Self-Hosted Integration Runtime:
- Purpose: Facilitates data movement between on-premises data
stores and Azure cloud services, or between private network environments.
- Location: Installed on an on-premises
machine or in a private network.
- Use Cases: Essential when accessing data
sources that are not publicly accessible over the internet, like on-premises
SQL Server, files stored on a local network, etc.
- Features: Can move data across different
network environments, ensuring data does not leave your private network.
- Azure-SSIS Integration
Runtime:
- Purpose: Designed specifically for running SQL Server Integration Services
(SSIS) packages in Azure.
- Location: Hosted in Azure.
- Use Cases: Suitable for businesses that
are migrating their existing SSIS workloads to Azure or require SSIS package
execution in the cloud.
- Compatibility: Supports most features of
on-premises SSIS but in a managed Azure environment.
How to create Integration Runtime (IR) in azure data
factory?
- Sign in
to Azure Portal: Go to Azure Portal and log in with your credentials.
- Navigate
to Your Data Factory: In the Azure portal, find and
select your Data Factory instance. If you haven't created one, you'll need to
create a Data Factory first.
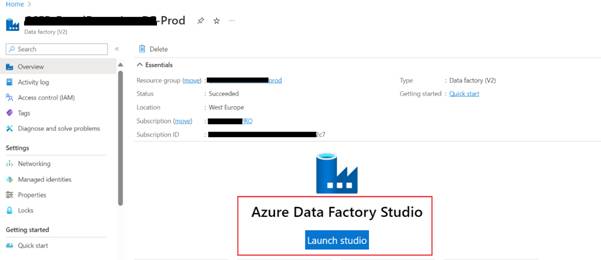
- Open the ADF Studio:
Once in your Data Factory, click on the "Author & Monitor" tile
to open the Azure Data Factory Studio.
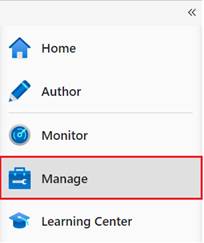
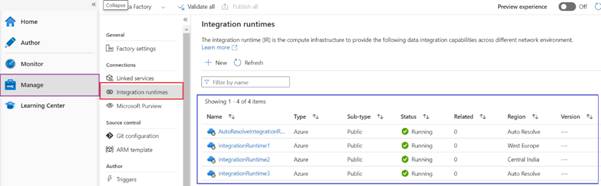
- Access the Integration
Runtimes: In the ADF Studio, go to the "Manage" tab,
which is located in the left-hand navigation pane.
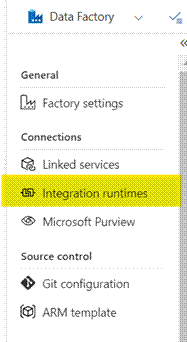
- Under the "Connections"
section, you'll find "Integration Runtimes." Click on it.
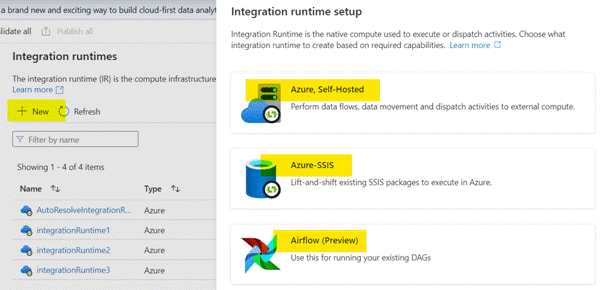
- Create a New
Integration Runtime: Click on the "+ New" button
to create a new integration runtime.
- You will be presented with options to
choose the type of Integration Runtime: Azure, Self-Hosted, or Azure-SSIS.
Select the one that suits your requirement.
- Configure the
Integration Runtime:
- For Azure
Integration Runtime: Simply provide a name for the IR and
configure the region where you want the IR to be hosted. The region should be
close to the data stores you are working with for optimal performance.
- For Azure-SSIS
Integration Runtime:
This option is for lifting and shifting existing SQL Server Integration
Services (SSIS) packages to Azure. You will need to specify the size and
location of the compute resources.sdfgsdf
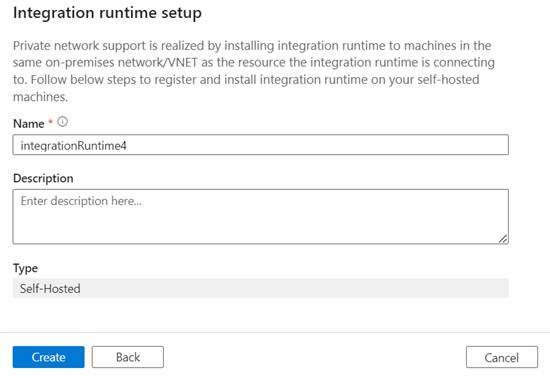
- For Self-Hosted
Integration Runtime:
- Provide
a name and description.
- After
creation, you will need to download and install the Self-Hosted Integration
Runtime software on the on-premises machine or virtual machine that you want to
use.
- During
the installation, you will enter a key that links your on-premises IR with the
Azure IR. This key can be obtained from the portal where you created the IR.
- Review and Create:
Review the settings for the IR. Once satisfied, create the integration runtime.
Azure IR will be provisioned immediately, while Self-Hosted IR will require you
to complete the installation process on your machine.
·
Monitoring and
Management: Once created, you can monitor and manage the IR
under the "Manage" tab. For Self-Hosted IR, you can also manage nodes
and update settings as necessary.
Key Features and Considerations
- Scalability and Performance: Azure IR automatically scales based on the workload. In contrast,
the performance of the Self-Hosted IR depends on the capabilities of the
machine where it's installed.
- Connectivity: Self-Hosted IR is crucial for scenarios where direct connectivity
to certain data stores is not possible due to network restrictions or when data
cannot be moved through the public internet for security reasons.
- Cost Implications: While Azure IR is managed by Microsoft and billed based on usage,
the Self-Hosted IR incurs costs related to the infrastructure it runs on and
its maintenance.
- High Availability and
Disaster Recovery: For mission-critical workloads,
configuring high availability and disaster recovery for IR, especially the
Self-Hosted IR, is important.
- Data Movement and
Transformation Capabilities: Azure IR is optimized
for high-throughput and low-latency network scenarios, making it ideal for
heavy cloud-based data movement and transformation tasks.
Best Practices
- Right Choice for Scenario: Choose the type of IR based on the specific requirements of your
data integration scenario, considering factors like location of data, network
requirements, and existing infrastructure.
- Security and Compliance: Ensure that the IR configuration adheres to your organization's
security and compliance standards, especially when dealing with sensitive or
regulated data.
- Monitoring and Management: Regularly monitor and manage the IR for performance, especially
the Self-Hosted IR, to ensure it's running optimally and is up-to-date.